Back to projects
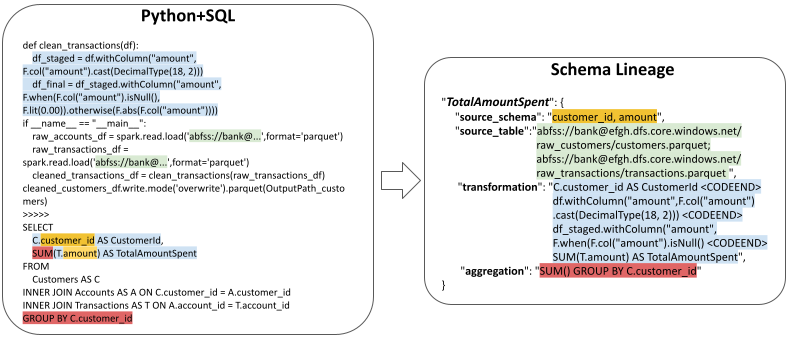
Highlights
- Built a benchmark with 1,700 manually annotated lineage examples.
- Introduced a composite evaluation metric to better reflect real extraction quality.
- Compared 12 language models across a difficult enterprise reasoning task.
Outcome
The project was accepted to the NeurIPS 2025 LLM Evaluation Workshop and the DL4C Workshop.